
过去几年,「AI+医疗」这四个字被说了太多次。但对大部分中国医生,尤其是基层医生来说,它常常只停留在PPT和新闻里——
1.指南更新太快,看不完;
2.病例越来越复杂,看不准;
3.门诊时间被不断压缩,顾不过来;
4.看完病人,还有大堆随访和表格等着填。
真正的问题,从来不是「AI有多炫」,而是:它能不能在你真正需要的时候,帮你做出安全、有效的决策,并且帮你把患者长期管好?
最近有一件事,可能会让你重新思考「医生用的AI究竟应该怎么做」这个问题。
01从一份国家文件说起:AI+基层,被放在了「C位」
就在上周,国家卫健委发布了《关于促进和规范“人工智能+医疗卫生”应用发展的实施意见》。

图源:国家卫健委网站
在「深化重点应用:人工智能+基层应用」部分,有两条被摆在了非常醒目的位置:
1.建立基层医生智能辅助诊疗应用
2.加强居民慢性病规范管理服务
这意味着什么?
AI不再只是大医院的“玩具”,而是被写进了国家层面的基层医疗优先级。下一阶段AI落地的「主战场」,就是中国基层。
长期深耕基层培训的多位主委在讨论时说得很直白:“这一次,文件已经点名要把AI真正落到临床、落到医生手里。”
而专家们也很快达成共识:
能真正帮到中国基层医生的AI,必须同时做到两件事:
1)诊中:辅助临床决策,要安全、有效;
2)诊后:支撑患者随访,要规范、可持续。
这,也是「未来医生AI工作室」诞生的起点。
02真正能上临床的AI,先看两件事:安全&有效
AI能背指南、写病历、考高分,并不等于能上临床。
北京大学第三医院运动医学科江东教授的判断很干脆:
“医疗AI的第一性原理,不是聪明,而是安全。”
那「安全、有效」怎么评判?不是拍脑袋,也不是看几道「秀操作」的题,而是一场严肃的、由医生主导的临床实战测评。
一场由32位临床专家主导的「多模型大比武」
1.26个专科、32位一线临床专家一起设计评估体系;
2.围绕「安全性/有效性」,搭建了一套可量化的临床评估标准;
3.从真实病历中抽丝剥茧,整理出2069道开放式问题;
4.统一用这些问题,去测评当时最前沿的6个主流大模型:
a.OpenAI-o3
b.Deepseek-R1
c.Gemini-2.5-Pro
d.Claude-3.7-Sonnet
e.Qwen3-235B
f.MedGPT(“未来医生”背后的医学大模型)
这项测评已于7月正式公开发布,并接受学术同行评议。

图源:arXiv:2507.23486
结果:AI总体不错,但在「安全」上,拉开了明显差距
1.在高风险问题上(药物相互作用、危重识别、并发症预警等),多款通用大模型得分明显下滑;
2.在涉及婴儿、儿童、免疫低下、慢病等易损人群时,有的模型会「偶尔很聪明,偶尔很危险」。
在高风险问题上,AI总体得分降低
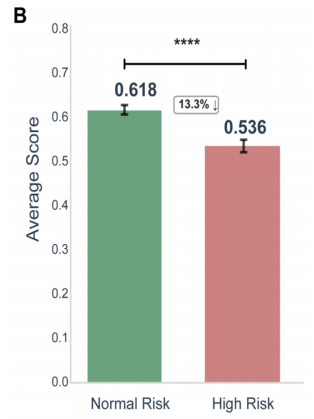
图源:arXiv:2507.23486
而在同一套标准下,MedGPT的表现有几个非常突出的特征:
1.总分领先第二名15.3%;
2.安全性得分比模型平均值高出近 70%(0.912 vs 0.547);
3.在复杂人群中,表现依然稳健,没有明显「翻车」。
总体得分、安全性、有效性,MedGPT(绿色)均领先
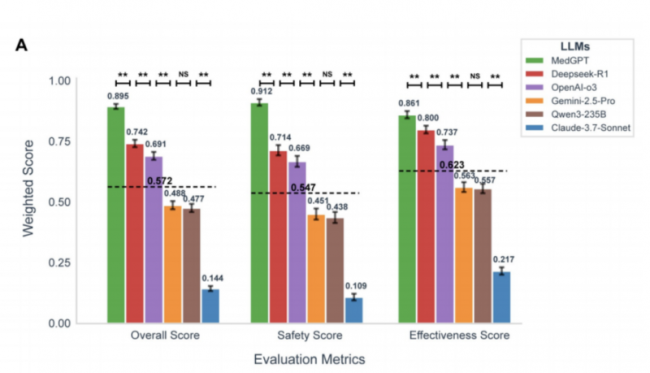
图源:arXiv:2507.23486
换句话说,这场比拼真正区分的,不是「谁更能聊天」,而是谁更适合被医生放进临床场景里一起工作。
江东教授复盘时说:
“临床不看偶尔答对,要的是次次不出错。”
从那一刻起,这个以MedGPT为底座的「未来医生AI工作室」,底色就被敲定了:不是去做“看起来很聪明的AI”,而是做“临床上最安全、最可靠的AI伙伴”。
03中国vs美国:同题实战里,比的不是「花活」,而是谁更像专家
说到这里,问题来了:如果把中国的MedGPT,和美国的GPT-5、OpenEvidence放在同一个临床场景下,让它们「真刀真枪」做决策,会发生什么?
中山大学附属第一医院泌尿男科邓春华教授,做过一次很有代表性的「同题实测」。
同题对决:GPT-5、OpenEvidence vs 未来医生 · 临床决策 AI 助手
他们做的事情很简单,但非常接近真实世界:
1.从实际工作中抽取一批复杂、有争议、信息不完全的病例;
2.同一道题目,分别交给三位「参赛者」:
A.GPT-5
B.OpenEvidence
C.未来医生·临床决策AI助手
请专家根据8个维度进行盲评,包括:
A.问题理解是否准确
B.鉴别诊断是否全面
C.风险点识别是否到位
D.治疗方案是否符合指南与本土实践
E.是否说明证据来源
F.是否提示信息缺口与需补充检查
G.表达是否清晰、结构是否便于临床使用
H.整体「安全性+临床可用性」
结果非常清晰:
在这套贴近中国临床场景的评估中,未来医生·临床决策AI助手,在多数维度上均优于GPT-5和OpenEvidence。
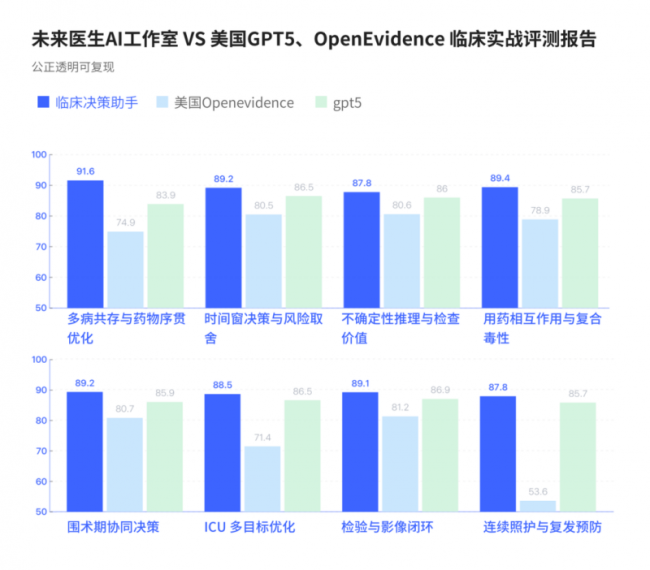
邓春华教授评价到:
“它会帮我看到盲区,启发我思考。这类思维链式的AI,能让基层医生也像专家那样看病例——有理、有据、有边界。”
这背后,是技术路线的差异:
1.通用大模型更擅长的是语言、知识与模式匹配;
2.而MedGPT的核心设计,是围绕“临床推理+风险控制”,搭建一整套医学认知框架,再在此之上做应用。
这也是为什么,在「中国医生vs美国医生,谁用的AI更强?」这个问题上,答案不再简单看「谁家的参数多、谁家的模型大」,而是看谁更接近医生真实的工作方式。
04临床决策AI助手:帮你「想全、想准、不出错」
信息不全、病例太杂、经验难积累——这是几乎所有基层医生共同的困境。
难点从来不是“查不到”,而是“没人陪你一起想”。
「未来医生·临床决策AI助手」要做的,就是这件事:
它不是一个“会背文献的数据库”,更像一个“随叫随到、愿意和你一起推理的专家同事”。

邓春华教授在使用未来医生AI工作室·临床决策AI助手进行决策辅助
一个典型的使用流程,大致是这样的:
1.医生输入病情概述/检查结果
可以是不那么规整的「口语化描述」
2.AI不急着给答案,而是先做三件事:
1).从高等级循证证据中抽取要点,搭建清晰的推理链;
2).提示风险点——药物相互作用、红旗征、高危人群等;
3).标出信息缺口——哪里还需要补充病史、体检或检查。
3.在此基础上,它会:
1).集成多位「专家智能体」的不同视角;
2).生成一份结构化的决策辅助报告,包括:
a.鉴别诊断列表及其理由
b.推荐检查及目的
c.可选治疗方案及循证等级
d.随访与复评建议
最终决策,仍然由医生做出,AI只负责「想全、想清楚、提示风险」。
对基层医生而言,这样的AI,带来的不是「命令」,而是一种思维上的托底感——
你依然是那个做决定的人,但不再是一个人默默承担所有不确定性。
05患者随访AI助手:把「规范化管理」搬进患者家门口
诊断只是开始,真正漫长的是诊后管理。
所有做基层慢病管理的医生都太熟悉这几个场景:
——电话随访打不完,表格录不完;
——患者忘复查、忘吃药,等到再来就已经「失控」;
——危险信号总是出现在「大家都很忙」的时候;
——你明知道该做规范化管理,却没有足够的时间和人手。
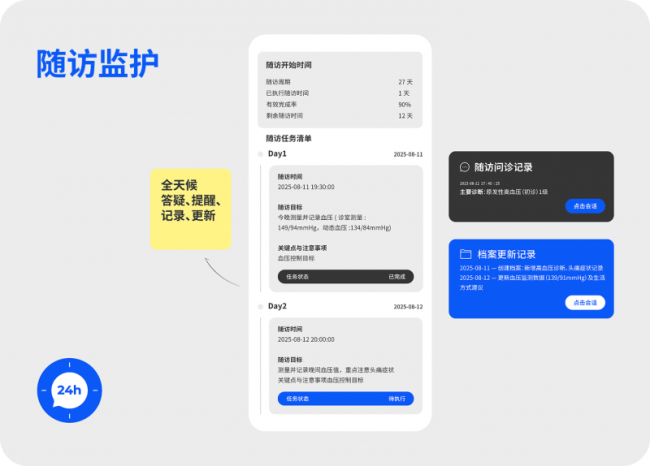
「未来医生·患者随访AI助手」要解决的,是这件看似琐碎、其实最难坚持的工作。
它的设计逻辑从第一天起就很清楚:
不是“替代医生”,而是“帮医生把该流程化的事情流程化、该提醒的事情提醒到”。核心是四个字:人机协同。
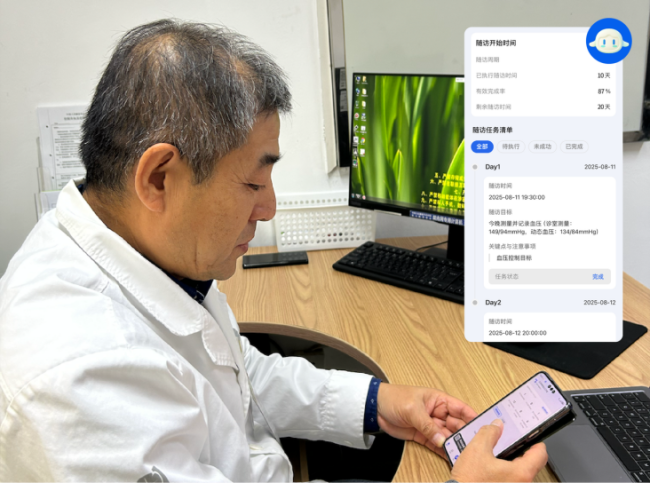
郭启煜教授在使用未来医生AI工作室·患者随访AI助手进行随访
它具体在做什么?
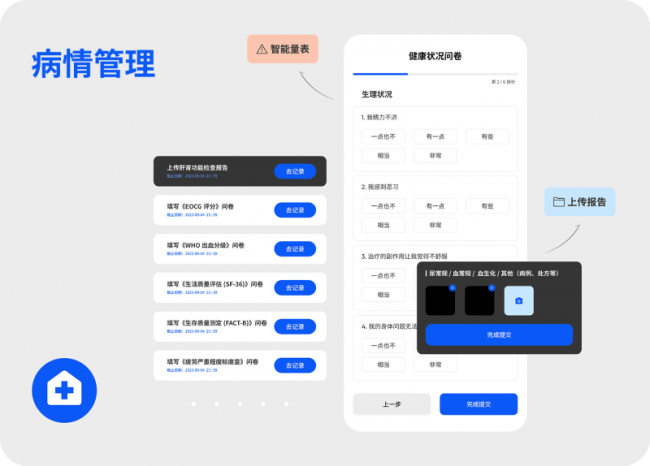
1.个体化随访方案自动生成
1).患者扫码上传病历/检查结果/日常记录;
2).AI根据诊断与指南,生成初步管理计划;
3).医生审核、修改、确认后,一键启动随访。
2.日常提醒与健康教育全自动
1).主动提醒复查时间、用药时间;
2).记录症状变化、生活方式执行情况;
3).推送与疾病阶段相匹配的健康科普。
3.关键事件智能上浮给医生
1).一旦涉及药物调整、新的严重症状等问题,系统不会「自作主张」,而是自动上报给医生,由你来决定。
2).当患者在对话中提到「胸闷」「头晕」「气短」「黑便」等高危词,系统会自动标记为高危预警,提示你优先处理。
看看它能为医生做什么



很多已经使用过的社区医生反馈:
“以前我得翻半天表格才能知道谁该复查,现在系统直接给我列出‘掉队的人’。”
而不少三甲专家,则把它形容为:
“一根延伸到院外的听诊器。”
——解放军总医院第六医学中心(海军总医院)内分泌科郭启煜主任说,
“它帮我看到那些已经出院、但仍需要被关注的人。”
06为什么主委们说:这是「基层+AI」目前看到的最佳实践?
当我们把所有拼图放在一起,就会发现一条非常清晰的逻辑链:
1.政策层面
1).「AI+基层应用」被写进国家「人工智能+医疗卫生」八大重点方向之首;
2).明确要求:既要有「基层医生智能辅助诊疗」,也要有「居民慢病规范管理」。
2.专家共识层面
多学科主委们达成一致:
真正能帮到基层的AI,必须同时做到:安全有效+人机协同。
3.技术验证层面
1).在多模型、多专科的大规模评测中,MedGPT在安全性与有效性指标上,全面领先一众国际主流模型;
2).在真实复杂病例的「同题对决」里,未来医生·临床决策AI助手,在临床可用性上优于GPT-5和OpenEvidence。
4.产品落地层面
1.「未来医生AI工作室」把技术真正落到了两个最关键、也是基层最缺的场景:
1.1.诊中:临床决策辅助;
1.2.诊后:智能随访与慢病管理。
2.这两大能力,已经在大量基层与专科门诊中日常运行,收获了来自一线医生的持续正向反馈。
也因此,当被问到「如何评价未来医生AI工作室」时,多位主委给出的答案出奇一致——
“这是目前看到的,最接近‘基层+AI’最佳实践的一条路。”
郭启煜教授说:
“我不追风口,只想把这个经得起医生验证的AI,交到每一位真正需要它的基层医生手里。”
07医疗AI的终局:不是替代,而是协同
每次谈到AI,总有人问:
“那以后医生会不会被替代?”
在和众多主委、专家的交流中,一个共同观点越来越清晰:
AI的强项,是快、全面、不知疲倦;医生的强项,是判断、取舍、经验与温度。真正的未来,不是谁替谁,而是谁补谁的短板。
如果说这几年,我们在「AI到底能不能做医生」这个问题上纠结了太久,那么接下来,也许更重要的问题是:
——在一个有AI的时代,我们能不能让每一位医生,都多一位值得信赖的搭档?
至少在这场「中国vs美国」的AI实战对比中,中国医生,已经开始用上一款在临床实战中打败GPT-5和OpenEvidence的中国医疗AI。
它不喧哗、不抢风头,却在门诊间、管理端、病房外,默默做着三件事:
1).帮你把病例看得更全一点;
2).帮你把风险想得更前一点;
3).帮你把患者守得更久一点。
或许在不久的将来,我们不再需要问「AI会不会替代医生」,因为它已经成为那盏灯——
既照亮医生的思路,也照亮患者回家的路。
如需体验,微信搜索“未来医生AI工作室”,即可进入超级医生个体时代。
(文中所涉测评方法与数据,均来源于公开发表的医学大模型安全性与有效性评估研究,以及GPT-5/OpenEvidence与「未来医生·临床决策AI助手」的临床决策辅助对比实测。)
